
About Server Sizing
In this blog post, I will spill my thoughts about server sizing on virtualization context, a topic which I learned recently from various articles. Server sizing is undoubtedly one of the most frequent questions for SRE interviews, so I decided to invest on this topic.
The goal is to give me ability determine whether I’m answering a server sizing question correctly or not.
Parameters
There are 4 criteria to consider before doing server sizing:
- memory
- CPU
- network
- disk resources (storage)
This criteria whatsoever has equally important properties and has no particular precedence over another. But, those criteria do have different focal points which could specify which one to check first.
Memory
You can check out the memory first, as it is typically a resource that most likely get exhausted first.
- Install maximum amount of RAM that the physical machine can give.
- When allocating memory for VM, use as little as possible memory.
- Avoid memory overcommitment, that is when you allocate more memory to the VM than the physical machine actually has.
- Memory overcommitment will not cause error, but it will make the server uses swap memory instead of physical memory and directly affect server performance as it increases CPU time
CPU
- The more core CPU has, more instructions it can handle at one time
- Each core can handle a set of instruction, for personal computer, usually the CPU possesses 1-4 cores, meanwhile for servers, on average could have 4 to 24 cores
- A good rule of thumb: A single core supports 4 VMs, this may vary from 1-2 VMs per core to 8-10 VMs per core
- When server sizing, you should always have at least one more core than the maximum number of vCPUs assigned to a single VM.
- More CPU core means more threads, usually each core can handle 2 threads. But there are also exist special processors that has 4 to 8 threads per core, like the SPARC processor.
- More threads means more task can be done simultaneously, which makes the CPU perfomance better and effectively faster dependending on how the program runs*.
In the middle of learning about this, I stumbled upon an interesting journal. In that journal it is said that there are actual formula to calculate a CPU demand at all times by its request amount.
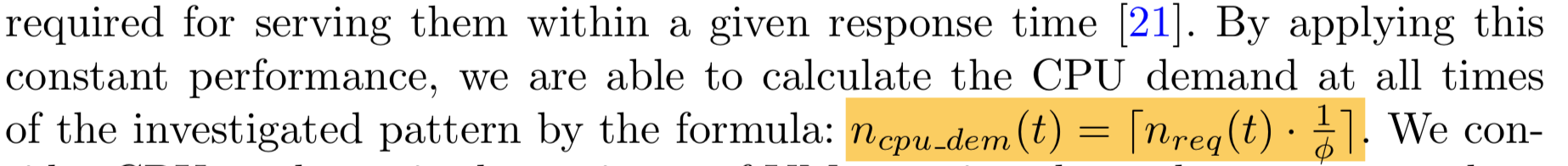
Note: We don't need all variables.
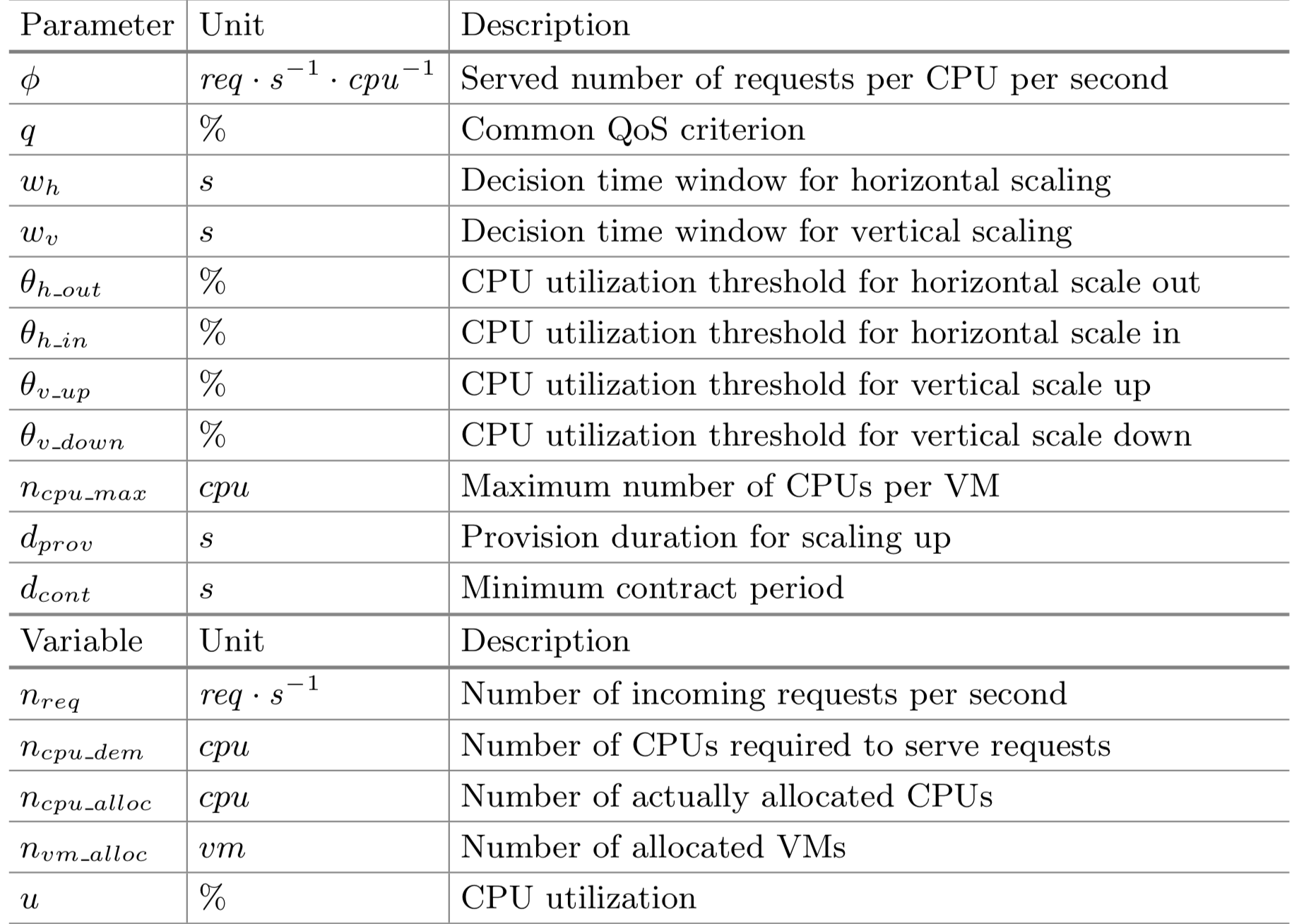
For example:
In an interview at Boogle, you are given this question:
Currently the server with 4 vCPU is handling 2000 request per second, at the peak hour the request will jump as high as 5000 request per second. How many vCPU you need to handle the requests during peak hour?
Answer:
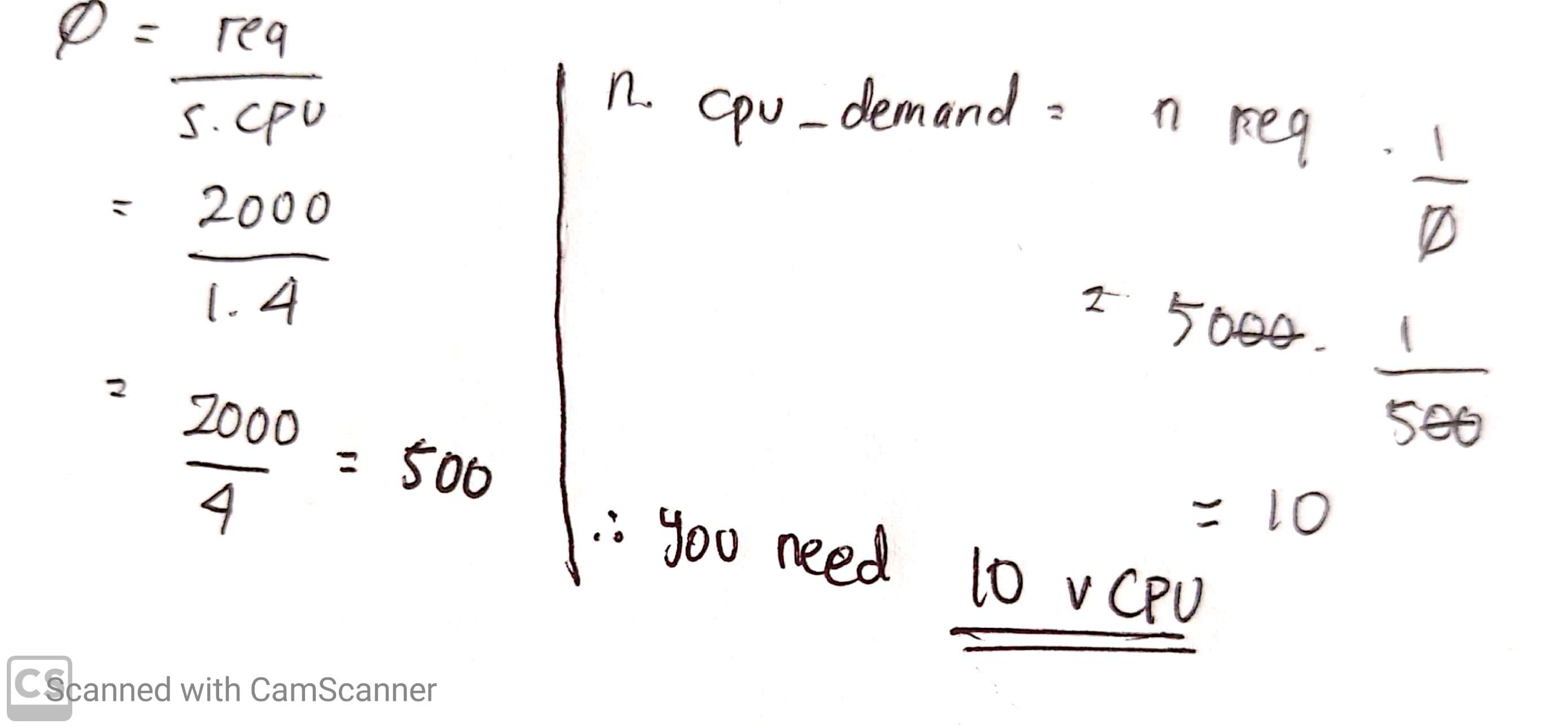
Note: Sorry for the bad handwriting :)
Network
- The amount of NIC is actually depends on the redundancy you would like to achieve.
- Use at least 4 network interface card (NIC).
- You may use more than 4 NICs if you use network storages.
When we’re talking about networks, we need to get a bit friendly with Quality of Service (QoS).
Quality of Service (QoS) is a measurement that used to determine whether a network has the ability to give its best quality for the traffic that passes through itself. QoS also used as network traffic prioritization and control mechanism by using parameters that the network defined, which could be useful to avoid network over-provisioning.
Commonly, QoS splits into 5 common parameters, this parameters could be different depending on the standard that the network uses.
- Bandwith
- Throughput
- Jitter
- Packet loss
- Latency
You can google how to manually count all of that parameters for measurement and which numbers are considered as “good” or “bad” QoS, but the point is you can control the congestion of your network by tuning those parameters.
Disk
- You can virtualize physical HDD as virtual hard disks or pass-through hard disks.
- Virtual disks retain its original disk and file format.
- SSD gives better performance than HDD. However, not all application needs SSD.
- More disks means more performance.
- More RAID group gives better redundancy, but not significantly improve the system performance.
- Rule of thumb #1: When provisioning add all storage used by the VMs + 10%-20% additional space for VM files and snapshot
- Rule of thumb #2: Use 80% of capacity of physical HDD for VMs, leaving 20% for spare
Discussion
*) If the program is complex enough that it can be broken down into several piece of instructions and the program enables the tasks to be done in parallel.
References
- https://searchservervirtualization.techtarget.com/tip/Sizing-server-hardware-for-virtual-machines
- https://www.kajianpustaka.com/2019/05/pengertian-layanan-dan-parameter-quality-of-service-qos.html
- [Laubis, K., Simko, V. and Schuller, A., 2007. Cloud Adoption by Fine-Grained Resource Adaptation: Price Determination by Diagonally Scalable IaaS. Communications in Computer and Information Science, [online] pp.249 - 257. Available at: https://link.springer.com/chapter/10.1007/978-3-319-33313-7_19 [Accessed 28 May 2020].]
28 May 2020